1 | 最近审计一个项目遇到了存在反序列化点但是没有利用链的情况,想尝试挖掘下利用链。目前挖掘利用链的工具主要是GadgetInspector和Tabby,原生的GadgetInspector跑了下效果并不理想而tabby可以根据自己的需要定制查询语法相对来说也比较灵活。本文主要是利用Tabby来分析下已知的利用链,一方面是熟悉tabby的使用和测试效果,另一方面是熟悉前辈们挖掘反序列化链的思路。 |
URLDNS
在java.net.url类的equals方法中,判断url是否相等的条件有两个。
- 引用相同
- 请求的URL的协议、端口、文件名、IP相同
1 | protected boolean equals(URL u1, URL u2) { |
既然有判断主机是否相同的情况,如果我们传入的是一个域名肯定要将我们传入的域名解析到IP,这就涉及到了DNS解析是由getHostAddress来完成的。
1 | protected boolean hostsEqual(URL u1, URL u2) { |
另外在java.lang.net计算hashcode时会分别获取请求协议、端口、文件、引用、主机等分别计算hash后进行拼接。
1 | protected int hashCode(URL u) { |
所以针对URLDNS这条链我们可以把sink定为java.net.URL#hashCode或java.net.URL#equals也可以直接将sink定为java.net.URLStreamHandler#getHostAddress,source自然是任意类的readObject了。
下面我们尝试用tabby挖掘下调用链,具体的环境搭建不讲了在作者的github上有详细的教程,有两个小问题要注意一下。
- 之前通过命令行直接运行jar总提示我target不存在,在配置文件
setting.properties中将tabby.build.target改成自己要分析的jar就可以了。 - 在分析过一次后,再运行tabby会一直卡在build class不动,这个是因为之前生成了缓存的数据库文件,删掉cache目录下的缓存文件即可。
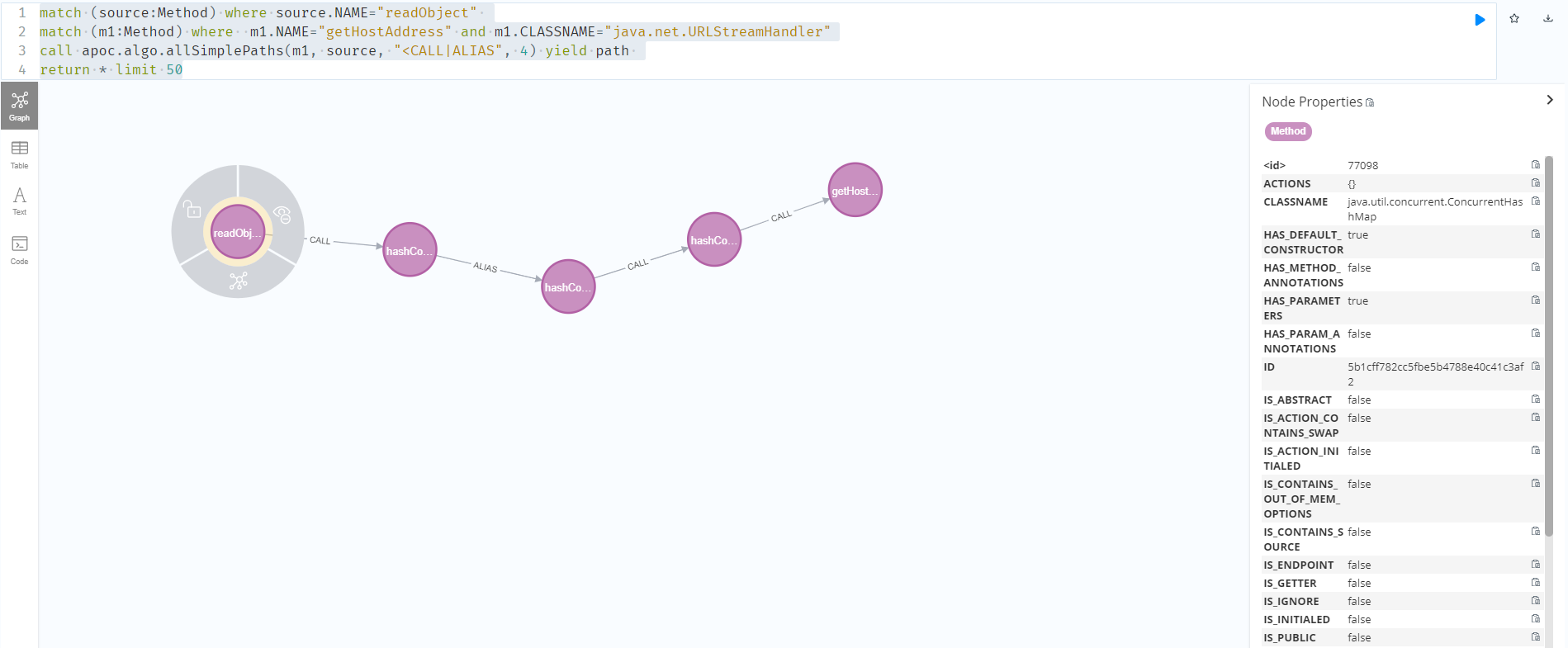
当选择调用链长度为4时,可以拿到从ConcurrentHashMap到getHostAddress的调用链。
1 | match (source:Method) where source.NAME="readObject" |
如果我们想找以java.net.URL#equals为sink的利用链,可以再对path做限制。
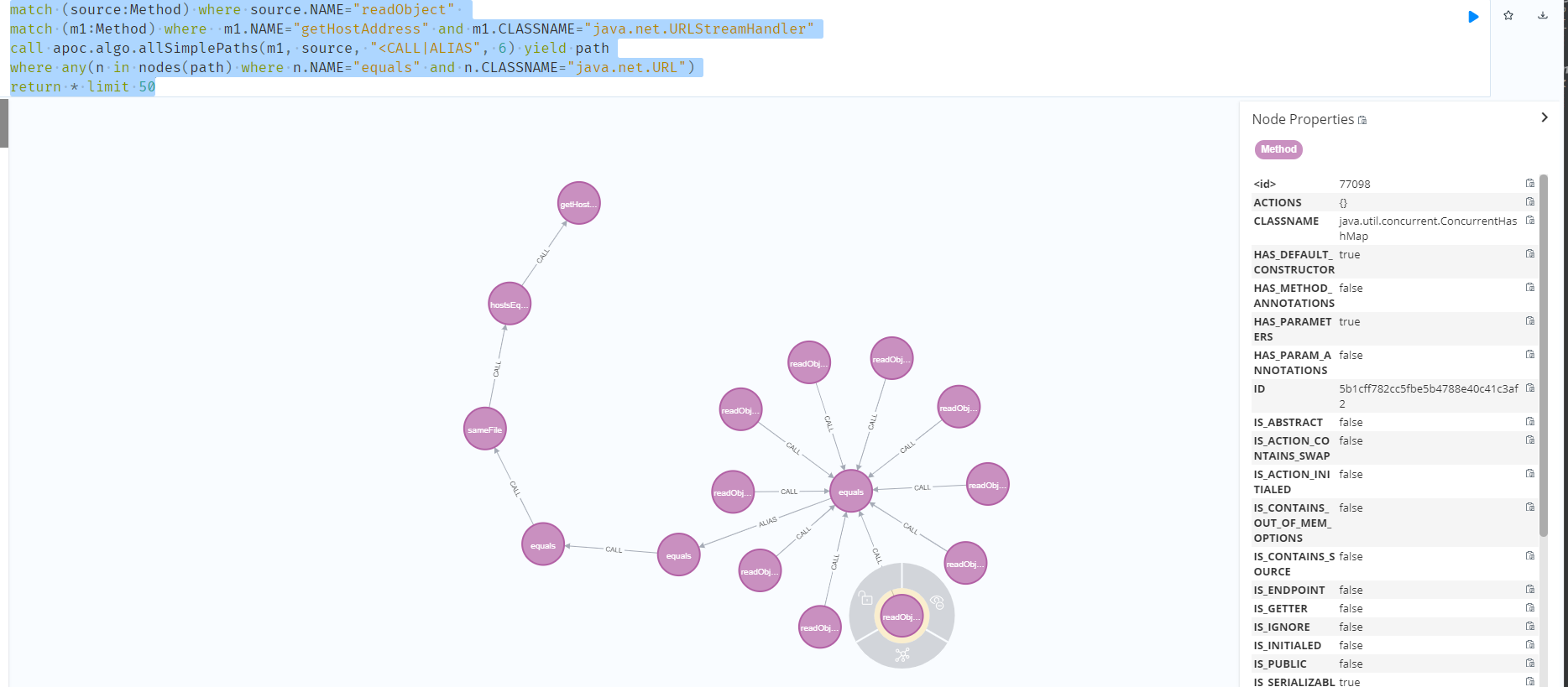
1 | match (source:Method) where source.NAME="readObject" |
当选择调用链长度为6时,可以拿到以java.net.URL#equals为sink的调用链。
Commons-Collections
CC1
CC1算是比较经典的反序列化利用链,一般来说我们通过一次反射是无法调用Runtime.exec方法执行命令的。因为Runtime类是不能序列化且没有public构造方法,而在CC1中通过ChainsTransformer进行多次Invoke实现了命令执行。 CC1的source有TransformedMap和LazyMap两条。
TransformedMap:当map的内容发生改变也就是调用put或者setValue方法时,会调用Transformer#transform方法对map的key或者value进行转换,而在AnnocationHandler#readObject中会获取属性中的map并调用setValue方法。LazyMap:LazyMap#get调用中key不存在时,会通过Transformer#tranform对key进行转换后,再将转换的结果put到map中,而在``AnnocationHandler#readObject`中也会获取属性中的map并调用get方法。
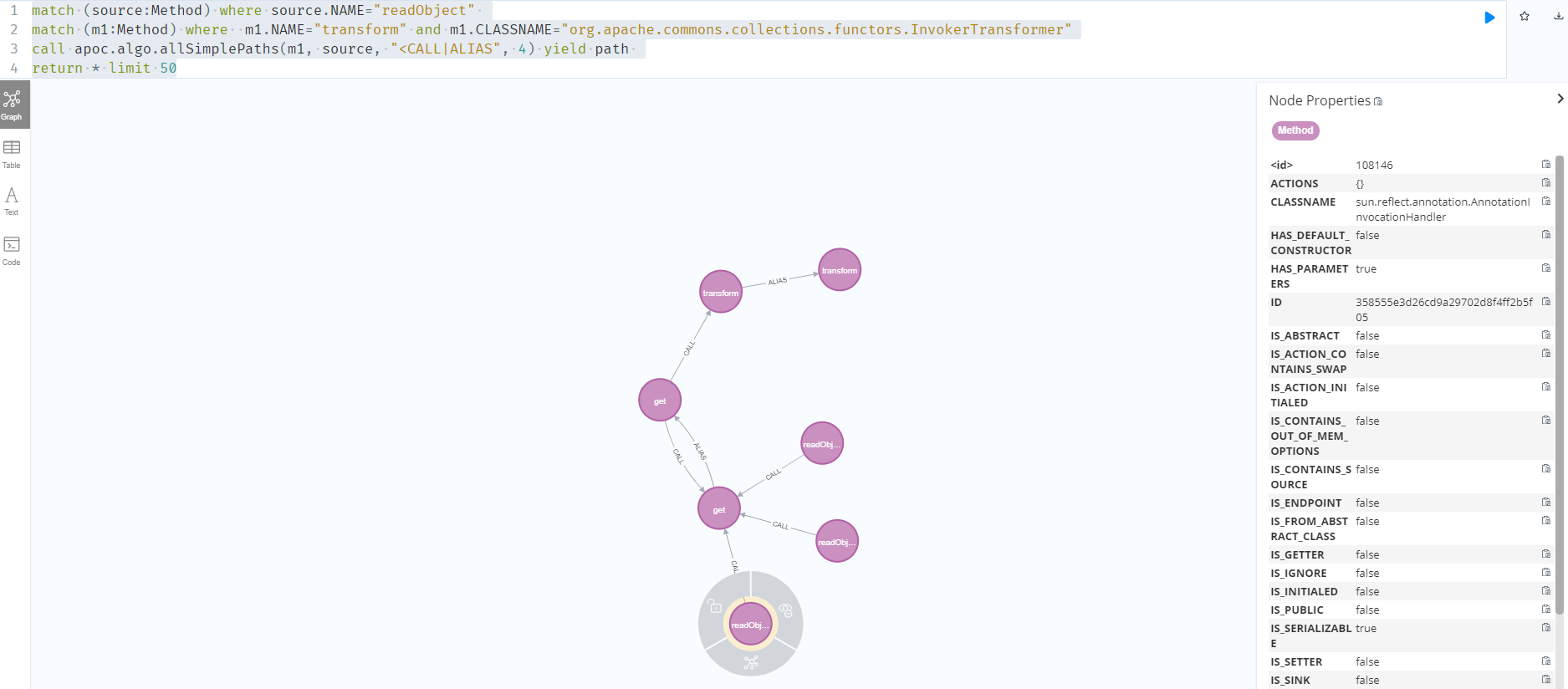
下面使用tabby获取从readObject到InvokerTransformer的调用链,指定ChainTransformer也可以。
1 | match (source:Method) where source.NAME="readObject" |
可以拿到LazyMap的调用链,如下所示:
我们要找从TransformedMap的利用链,尝试在路径中做一些限制。
1 | match (source:Method) where source.NAME="readObject" |
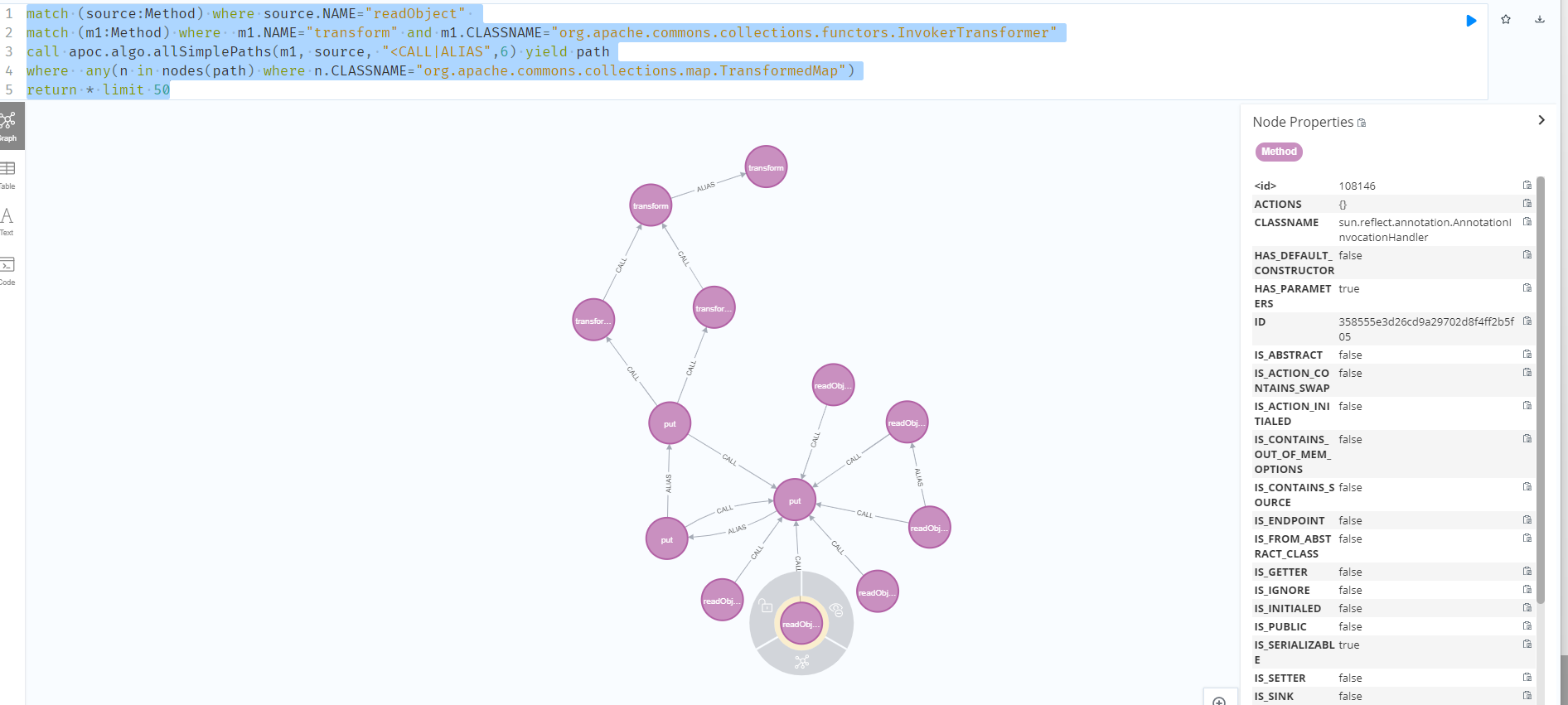
这里并没有拿到TransformedMap#setValue的调用而是拿到了map#put的调用,这是因为在JDK8中调用了map#put但这个map的类型并不可控,所以算是误报吧。
1 | private void readObject(ObjectInputStream var1) throws IOException, ClassNotFoundException { |
CC2
PriorityQueue是一个优先级队列默认情况下使用自然排序,也可以指定不同的Comparator来对元素排序。在进行反序列化时会调用Comparator#compare对元素进行比较后排序。TransformingComparator是Comparator的实现类其compare实现中首先通过Transfromer#transform对元素修饰后再进行比较。由于TransformingComparator在3.1没有实现Serializable接口,因此CC2只能在4.4版本使用。
1 | public int compare(Object obj1, Object obj2) { |
下面通过tabby拿到CC2的利用链
1 | match (source:Method) where source.NAME="readObject" |
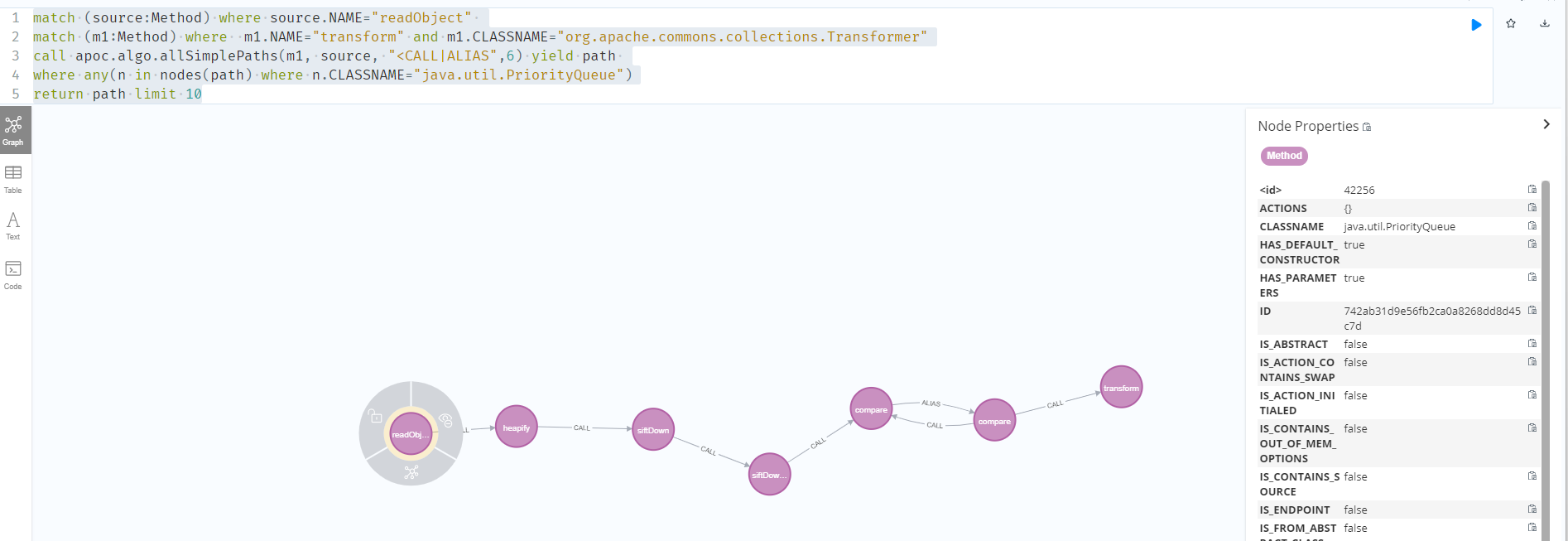
CC3
CC3应该是Commons-collection里比较特殊的利用链了, 因为并没有使用InvokeTransformer作为sink。在CC2中我们了解到可以通过构造一个恶意的TemplatesImpl 对象,当目标调用newTransformer 加载提供的字节码并实例化导致静态代码块和构造方法的执行。在 CC2中是使用了InvokeTransformer通过反射调用了newTransformer,那么有没有可能直接通过某个方法调用newTransformer呢?
在CC3中提出了通过com.sun.org.apache.xalan.internal.xsltc.trax.TrAXFilter构造方法调用newTransformer。
1 | public TrAXFilter(Templates templates) throws |
所以我们只要找到从readObject到TrAXFilter的利用链即可,而触发点是在TrAXFilter的构造方法触发的,只要找到一个方法可以调用构造方法并传入参数即可。
直接通过tabby拿到的利用链比较多,我这里直接通过条件限制transform方法,可以直接拿到利用链。
1 | match (source:Method) where source.NAME="readObject" |
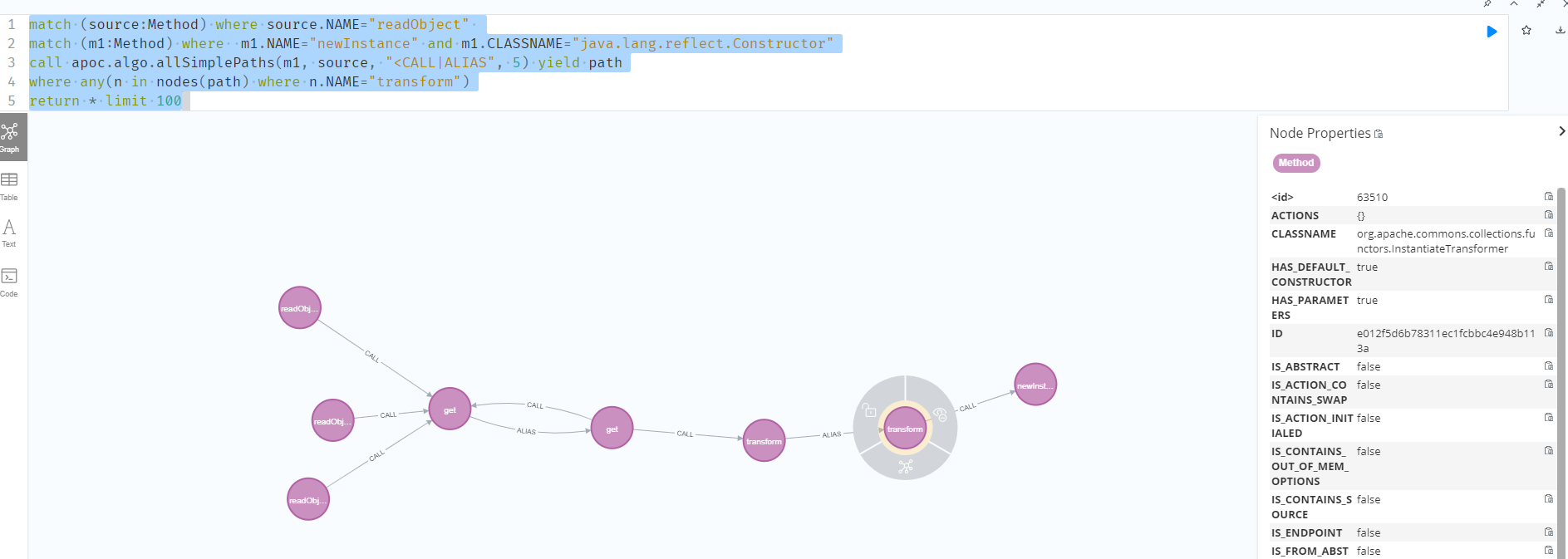
CC4
CC4比较简单相当于CC2和CC3的组合没什么可说的,在参考这篇文章发现作者找到了其他的source来进行触发。作者的思路是寻找其他类替代PriorityQueue,这个类的可以通过readObject调用到compare方法,最终找到了TreeBag。
Bag 接口继承自 Collection 接口,定义了一个集合,该集合会记录对象在集合中出现的次数。它有一个子接口 SortedBag,定义了一种可以对其唯一不重复成员排序的 Bag 类型。
TreeBag 是对 SortedBag 的一个标准实现。TreeBag 使用 TreeMap 来储存数据,并使用指定 Comparator 来进行排序。
1 | match (source:Method) where source.NAME="readObject" |
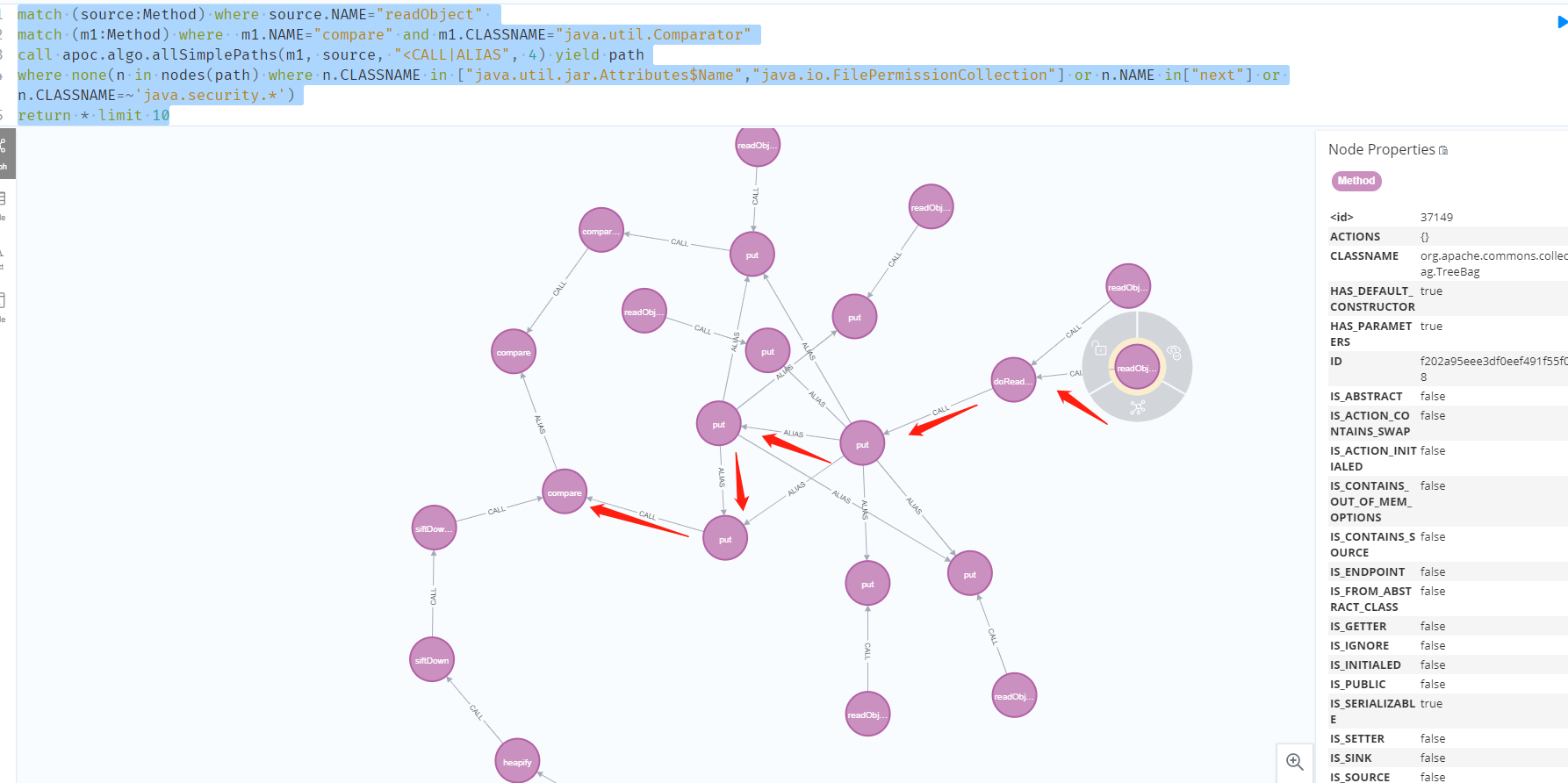
除了TreeBag还有HashBag也可以作为source。
CC5
在分析CC1时我们知道LazyMap#get可以触发漏洞,但是由于AnnocationHandler在JDK8中做了修复,无法调用自定义map的get方法也就导致CC1无法在高版本JDK中使用。如果要适配高版本,我们需要找到一条从readObject到map#get的路径。
1 | match (source:Method) where source.NAME="readObject" |

通过上面的语法拿到了从Flat3Map到map#get的利用链,看上去也没什么问题,但是实际利用中存在下面的代码,只有存入第一个map的key hash1等于第二次传入的key hashCode时才会调用equals方法。
1 | else if (this.size > 0) { |
但是我们需要的利用链中key应该为HashTable key1为lazymap才能触发漏洞。而且hash1使用transient修饰,我们也无法在序列化前通过反射修改hash1内容。
1 | HashTable#equals |
直接使用map#get作为sink得到的调用链过多可以先找上层调用。
1 | match path=(m1:Method)-[r:CALL]-(m2:Method{NAME:"get",CLASSNAME:"java.util.Map"}) where m1.CLASSNAME=~'.*org.apache.commons.*' return m1.CLASSNAME,m1.NAME,m1.PARAMETERS |
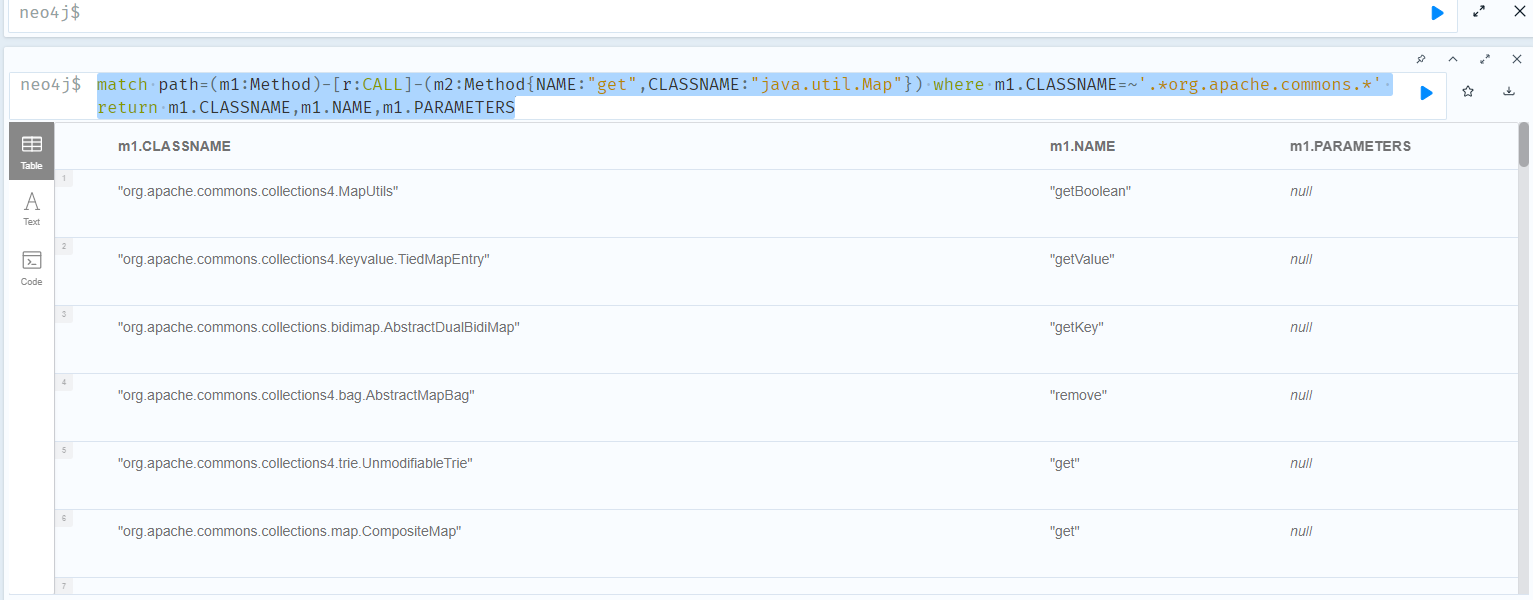
其中下面的类不能作为sink
- org.apache.commons.collections4.MapUtils 不支持序列化
- org.apache.commons.collections.bidimap.AbstractDualBidiMap 不支持序列化
- org.apache.commons.collections.bag.AbstractMapBag map属性不可序列化
- org.apache.commons.collections4.trie.UnmodifiableTrie 属性是Trie类型
- org.apache.commons.collections.functors.MapTransformer 已经能调用到transformer就不需要再找sink了
- org.apache.commons.collections.CollectionUtils 不支持序列化
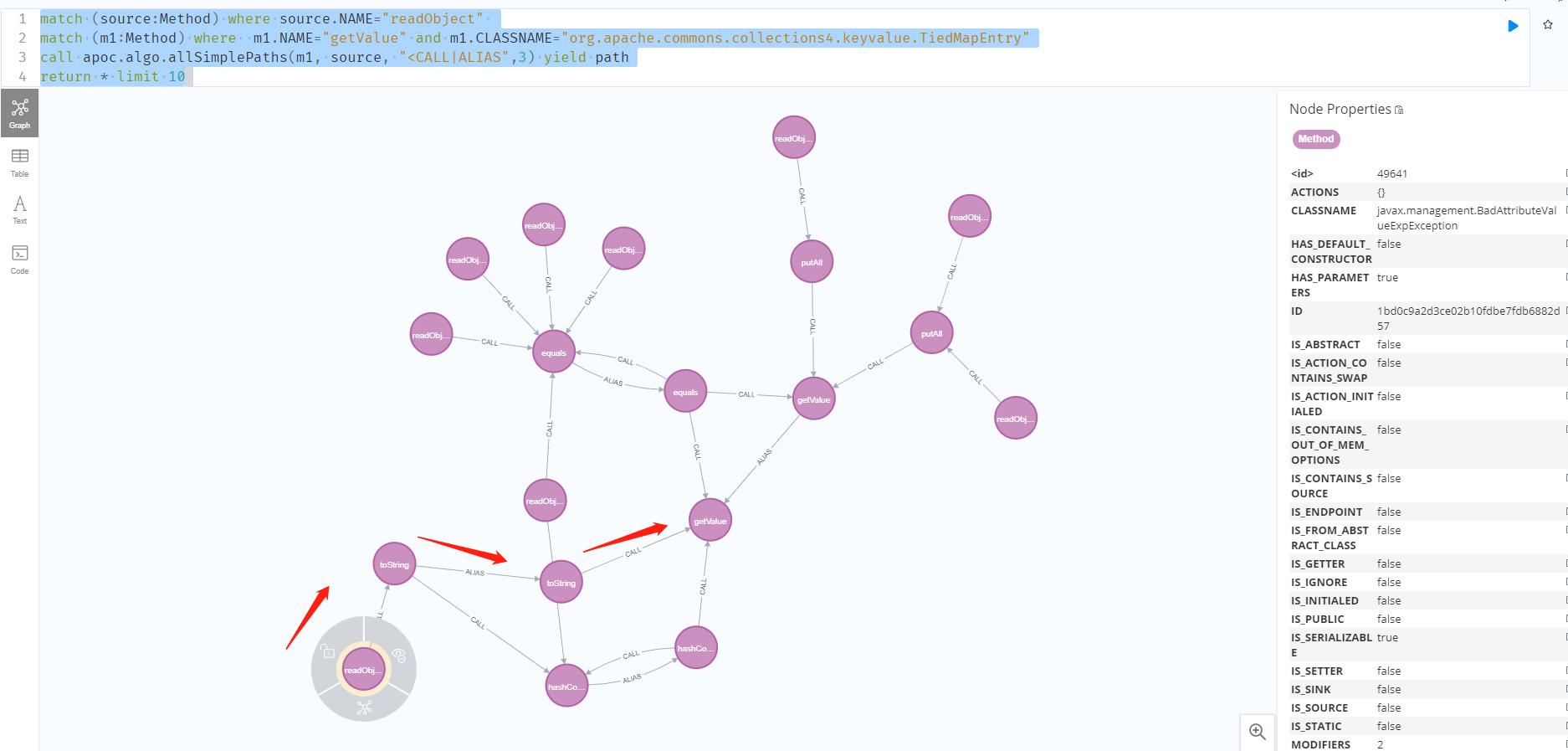
org.apache.commons.collections4.keyvalue.TiedMapEntry可以作为source,因为map属性是可控的并且这个类支持序列化。

1 | match (source:Method) where source.NAME="readObject" |
总结
首先从利用链的挖掘来讲,多数的利用链都是在已有利用链的基础上变换组合产生的,因此多了解已有的利用链是非常必要的。针对CC链,在4.4.1中InvokerTransformer、InstanseTransformer不再支持序列化。而除了CC3以外其他的利用链都会用到InvokerTransformer,所以已经不太可能从CC中找到sink了,不过抛开CC组件来看,如果能找到一个替代InstanseTransformer的类可以实例化TrAXFilter也有可能产生新的利用链。
从tabby的使用上来讲,由于路径过深或查询条数过多都会在一定程度上影响分析也比较吃电脑性能,所以想直接去分析readObject到invoke调用可能不太容易直接拿到结果,还是建议从已有的source常见的点出发或者确定了对应的sink的基础上再去分析,如果到某一层感觉不太好分析,可以找上层的调用作为sink缩小查询范围。查询语句比较灵活可以根据自己的需求和想法组合语句算是tabby的优势吧。