最近做项目遇到存在漏洞的fastjson,虽然最终还是打下来了,但是要深入利用如果不了解原理就比较难受,因此专门花时间了解下fastjson反序列化漏洞形成的原理。我不想长篇大论的去写很多关于fastjson的问题,主要是解决我这个没接触过fastjson漏洞的一些疑惑。
有没有特殊编码可以绕WAF?
之前做渗透,当json数据包中出现"@type":"com.sun.rowset.JdbcRowSetImpl"数据包就会被拦截,因此分析下有没有替代方案可以绕过WAF。
在com.alibaba.fastjson.parser.DefaultJSONParser#parseObject(java.util.Map, java.lang.Object)中会对JSON进行词法解析。当解析到第一个内容是,时,会忽略后面的,和其他空白字符。
所以使用下面的内容仍然可以解析。
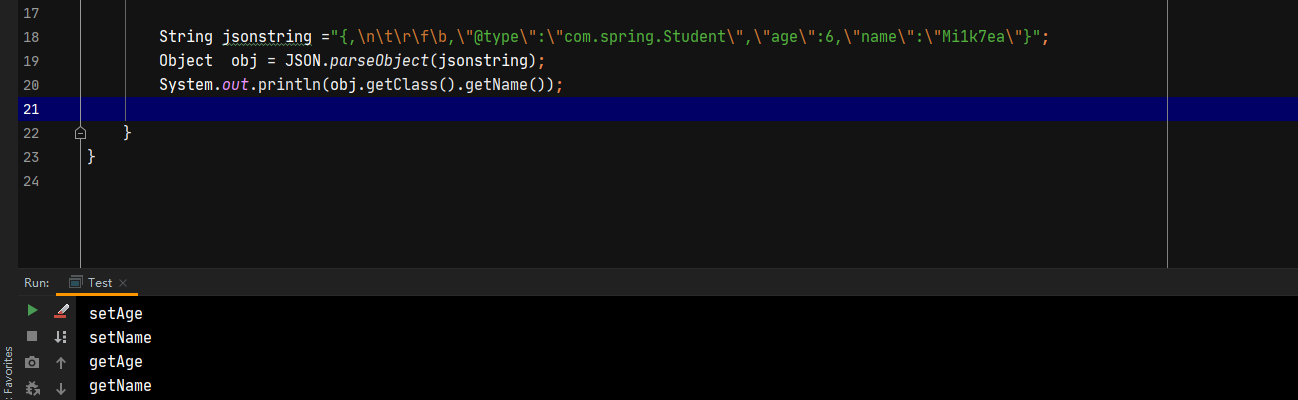
当解析的内容为”,会通过scanSymbol解析key的内容,当当前的内容为\会进入if的逻辑。

下面会解析\后的字符,根据\后的字符执行不同的操作。
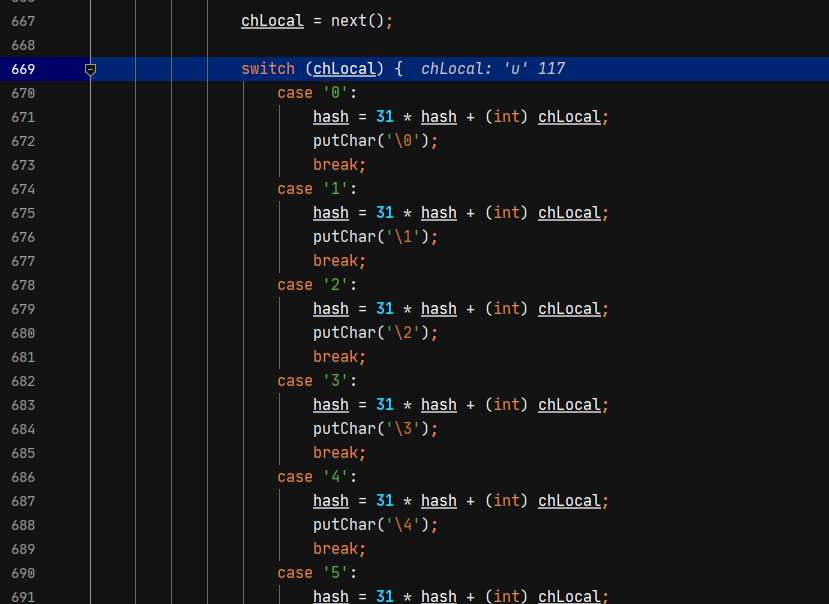
当解析到\x或\u会取后面的内容会接收内容并转换成char。所以可以通过16进制或unicode编码绕过拦截。
1 | @\u0074ype -> @type |
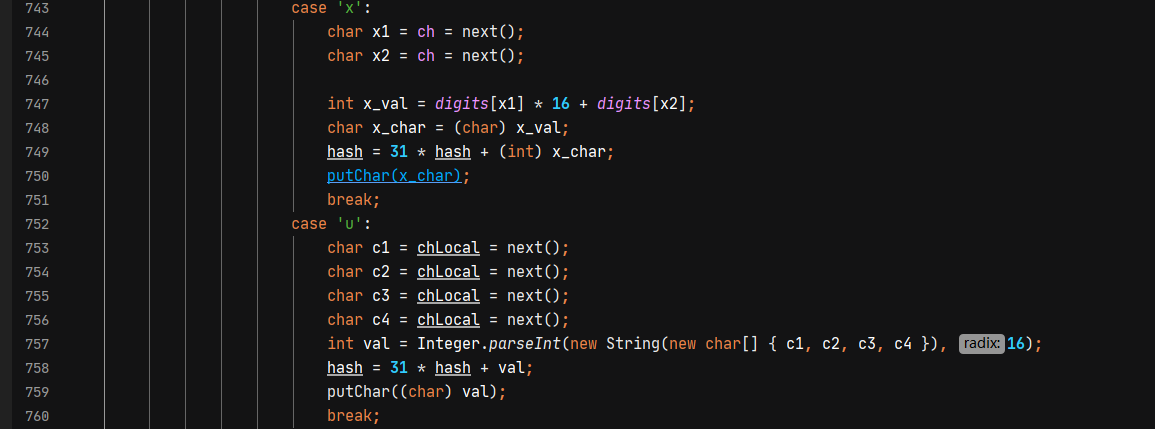
获取key后,继续调用skipWhitespace对后面的内容进行处理,会将:前的空字符替换为空。所以下面的内容也不会影响解析{\"@type\"\t\n\r:\"com.spring.Student\",\"age\":6,\"name\":\"Mi1k7ea\"}


在往下走,将:后和空白字符也替换为空。

当key的内容为@type,会进入if语句中,并且再次通过scanSymbol获取value的内容,所以value也可以使用十六进制或者unicode编码绕过。

下面通过com.alibaba.fastjson.util.TypeUtils#loadClass(java.lang.String, java.lang.ClassLoader)加载value对应的类的信息。注意下面,当以L开头并和;结尾,会去掉这两个字符并重复调用TypeUtils#loadClass,所以Lcom.spring.Student;或者LLcom.spring.Student;;都会解析出com.spring.Student,所以也可以通过这种方式绕过。

所以总结一下,绕过方法如下
1 | 1. 在@type的双引号前加,和其他空白字符,比如 \b \n \t等等 |
反序列化过程中会调用什么方法?有何限制?
通过ClassLoader加载到@type指定的类后,接下来会根据类名获取对应的反序列化器,当没有匹配到合适的反序列化器时,会通过createJavaBeanDeserializer创建JavaBeanDeserializer反序列化器。createJavaBeanDeserializer反序列化器中,调用JavaBeanInfo.build方法中动态创建一个JavaBeanInfo对象,最后根据得到的JavaBeanInfo对象,通过asmFactory.createJavaBeanDeserializer动态构建一个JavaBeanDeserializer类。
首先通过getDefaultConstructor获取构造器
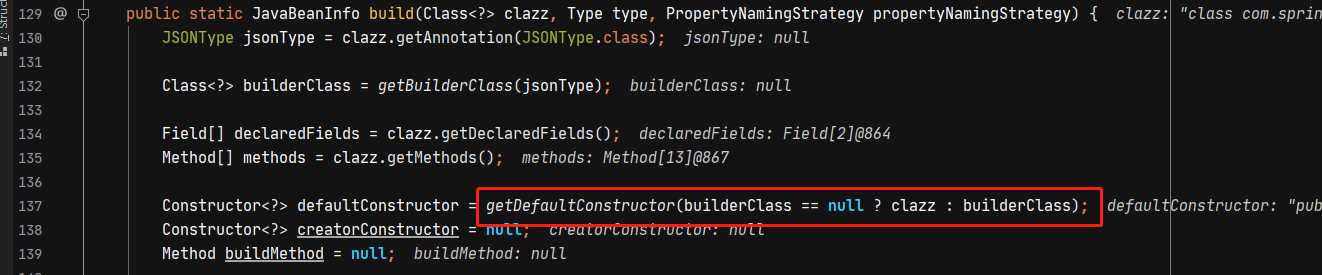
在getDefaultConstructor默认会获取无参构造器,如果不存在无参构造器,则获取参数为当前Class类型的1个参数构造器。
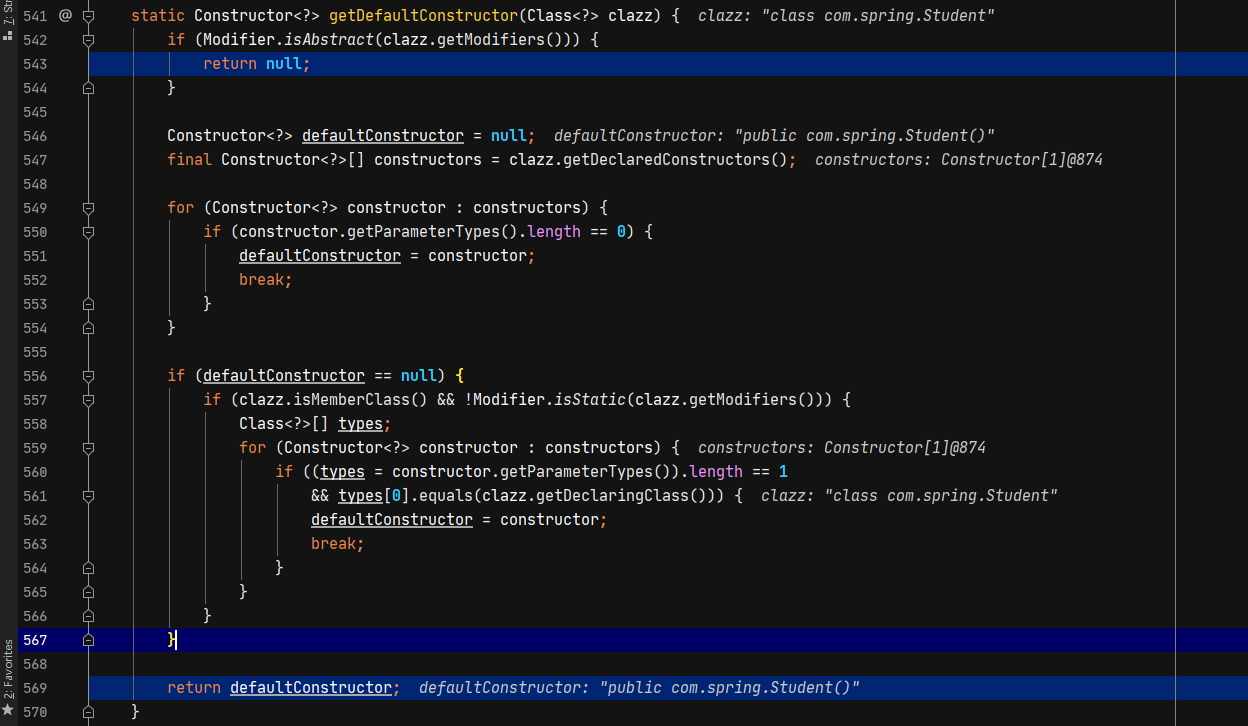
如果没有无参构造方法或者参数为当前class类型的有参构造方法,则通过注解获取构造方法,对于挖洞或者利用漏洞来讲,我们一般找的会是一个通用的类,一般不会有fastjson的注解信息,所以这段不分析了。
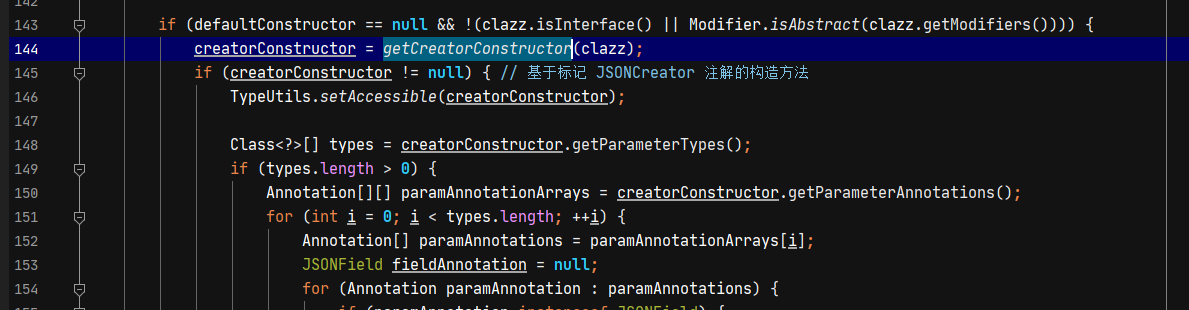
总结一下构造方法的调用。
1 | 1. 默认情况下调用无参构造方法, |
下面再看看对setter method的处理
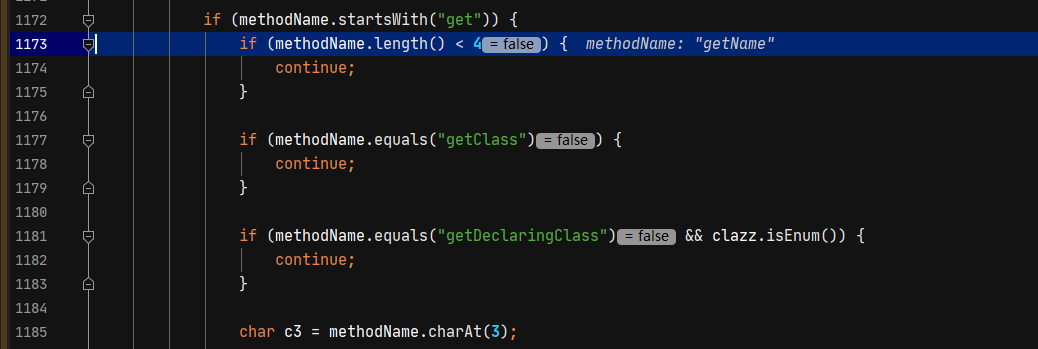
1 | 1. methodName名称大于4 |
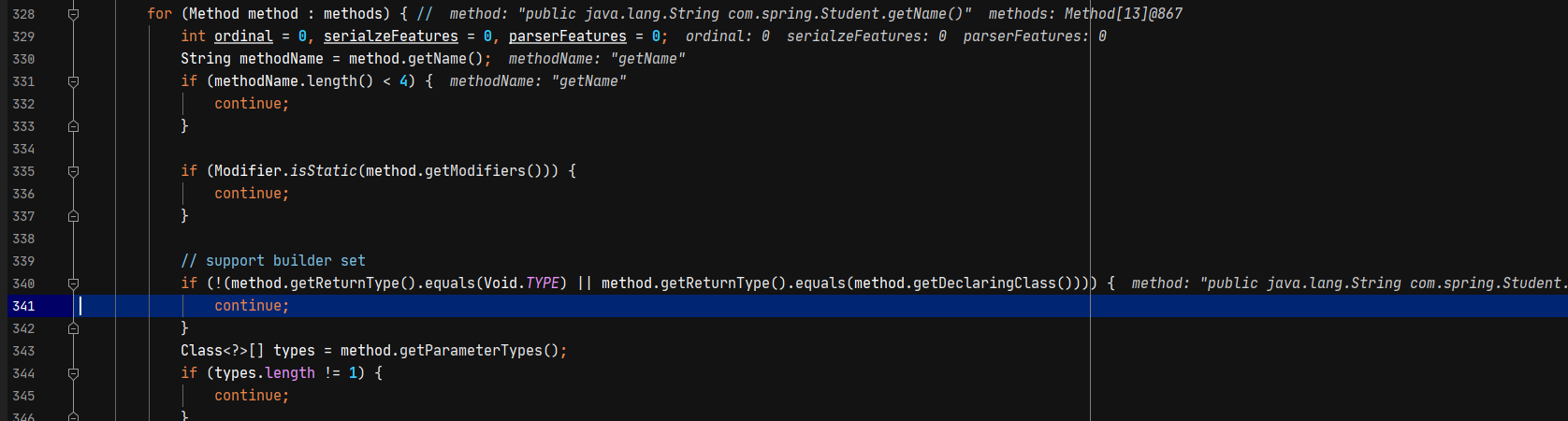

接下来找到set方法设置的字段名,并将这些信息添加到fieldList中。

下面也会对getter方法做判断,但是对getter方法的返回值有一些要求,不太容易满足。
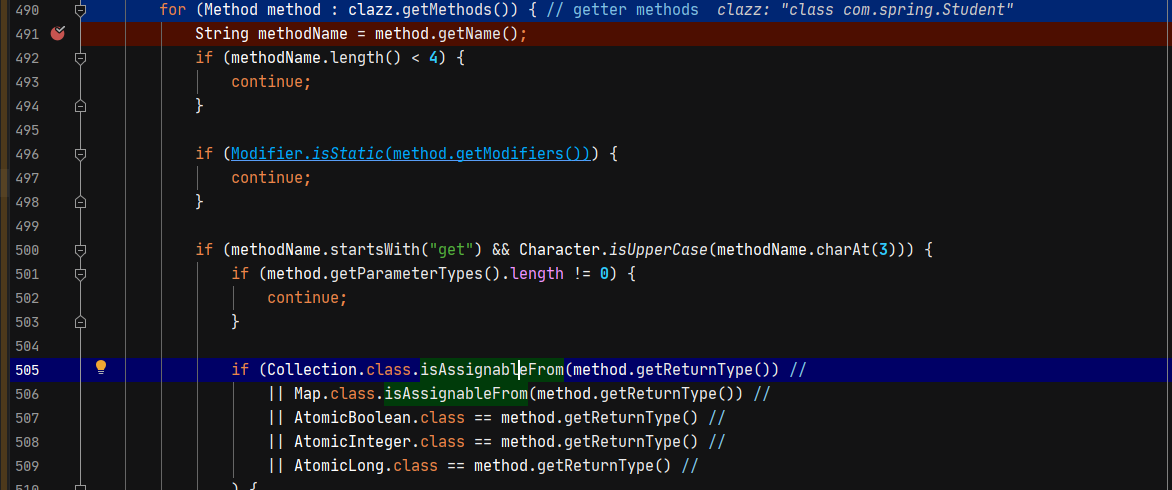
接下来将得到的class,构造方法,filed等信息封装到JavaBeanInfo对象中并返回。
得到JavaBeanInfo后,通过asm动态创建JavaBeanDeserializer的实现类。

我们不去分析具体的生成过程,把动态生成的class文件看看即可。
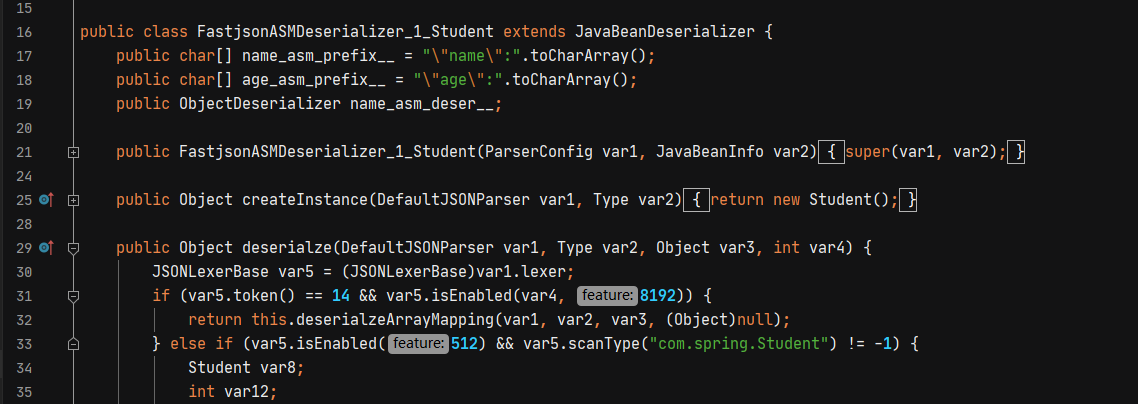 这个文件比较长,在
这个文件比较长,在deserialze中,会调用构造方法,还有对应的setter方法。
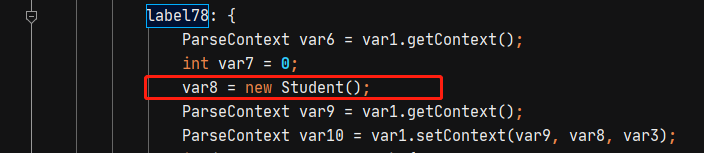
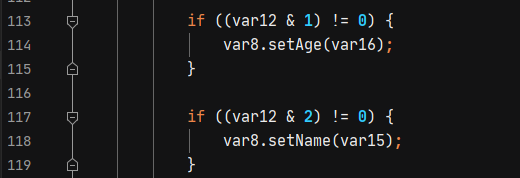
通过parse反序列化得到对应的对象后,会判断反序列化得到的对象类型是否为JSONObject类型,如果不是则调用toJSON进行类型转换。

在toJSON中,根据obj的类型得到clazz,根据clazz通过 config.getObjectWriter(clazz);获取由ASM动态构建的继承了JavaBeanSerializer的序列化器,这个过程和pase的过程有些类似,不同的是,得到序列化器时构造beaninfo信息时通过com.alibaba.fastjson.util.TypeUtils#computeGetters方法,computeGetters中会对getter方法进行限制。
1 | 1. 非静态方法 |
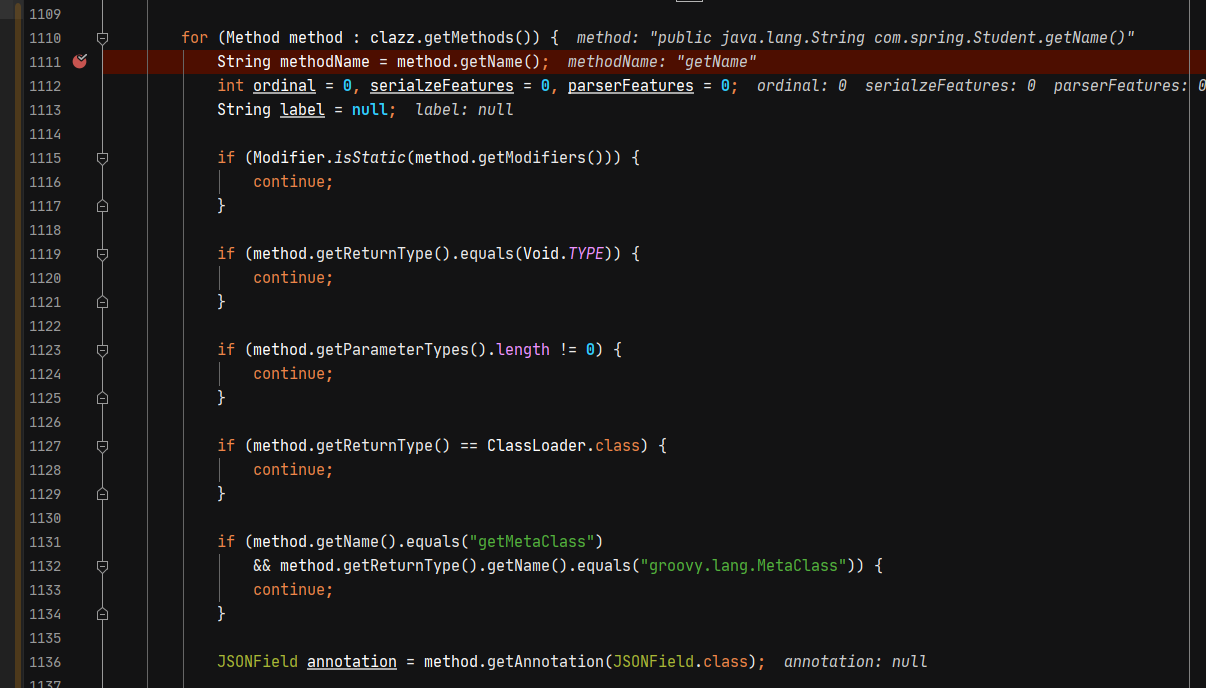
将filed method等属性封装到FiledInfo中。

得到动态构建的序列化器后,调用getFileValuesMap获取字段的值,由于ASM动态构造的反序列化器没有这个方法,因此会调用父类JavaBeanSerializer的getFieldValuesMap方法。


getFieldValuesMap中,根据sortedGetters中保存的FieldSerializer,调用getPropertyValue方法,实际最终是通过反射调用了对应的getter方法。


反序列化利用链原理是什么?
通过上面的分析,当执行parseObject时,会执行构造方法和setter和getter方法,所以我们要通过控制getter和setter方法来对属性赋值从而执行恶意操作。
TemplateImpl
这个利用方式之前分析Hibernate利用链时分析过,其实fastjson的利用限制和hibernate的差不多。

通过之前我们对TemplatesImpl利用链的理解,我们需要对下面的属性赋值。
1 | 1. _bytecodes |
并且其存在无参的public构造方法或者参数为当前类型的构造方法。而TemplateImpl类刚好有无参的public构造方法。

另外,触发TemplatesImpl的方法是getOutputProperties方法,也就是一个gettter方法,只有在parseObject方法中,才会在执行完parse后调用toJSON,在toJSON中调用getter方法,所以这也限定了只有在通过parseObject解析时才可以使用TemplatesImpl利用链。
如何给_bytecodes传入字节数组?
在不了解fastjson内部实现的情况下,我们可以构造一个字节数组,通过toJSONString进行序列化,并查看序列化后的结果,可以看到fastjson将字节数组进行base64后输出。
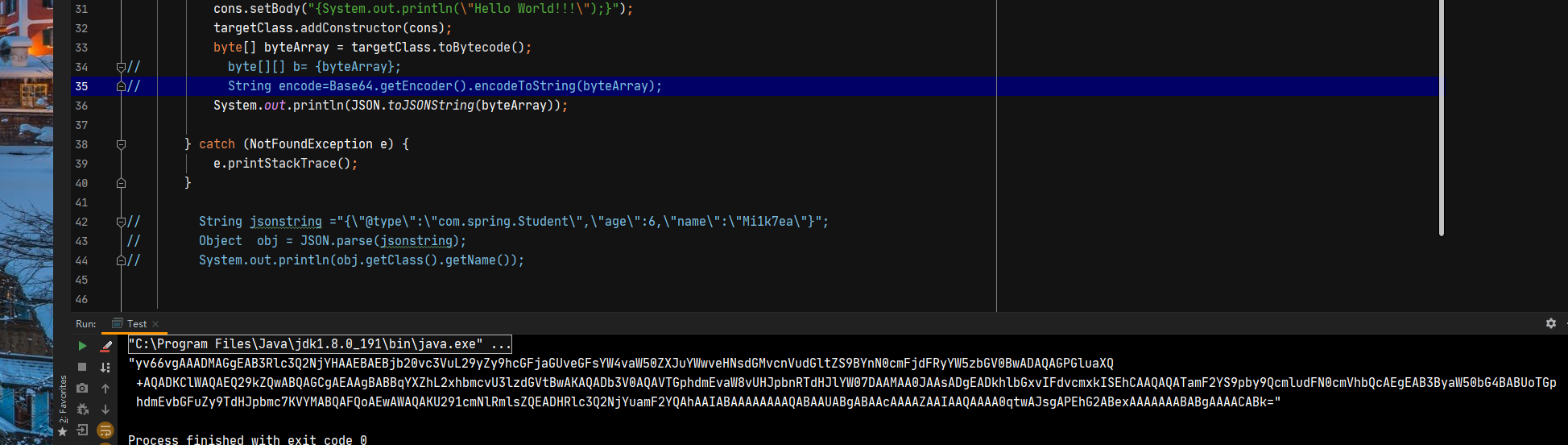 . 跟进fastjson序列化代码,首先通过getClass获取对象类型,再找到对应的序列化器,而我们传入的byte数组会交给PrimitiveArraySerializer序列化器进行处理,PrimitiveArraySerializer的write方法,根据数组的类型进行匹配,当匹配到为字节数组,则通过writeByteArray进行base64编码。
. 跟进fastjson序列化代码,首先通过getClass获取对象类型,再找到对应的序列化器,而我们传入的byte数组会交给PrimitiveArraySerializer序列化器进行处理,PrimitiveArraySerializer的write方法,根据数组的类型进行匹配,当匹配到为字节数组,则通过writeByteArray进行base64编码。

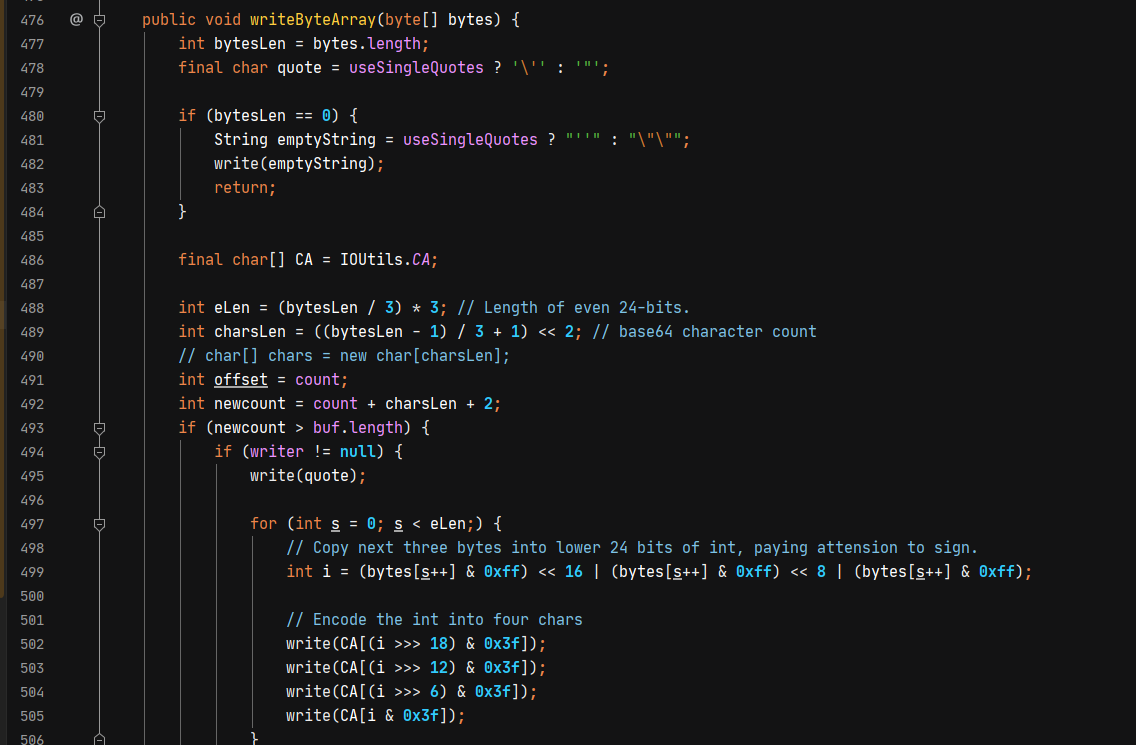
所以可以通过base64编码解决byte[]传值问题。
为什么getOutputProperties会被执行?
虽然有对应的setter方法可以给 _name和_bytecodes属性赋值,但是这些方法都不是public的,所以默认情况下都不能调用,但在fastjson1.2.22引入了一个SupportNonPublicField特性,可以给非public的属性赋值 ,所以要使用这种方式,需要在反序列化时开启这个属性。可是开启了这个属性后,就会调两个参数的parseObject方法,在这个方法中并不会执行toJSon方法,也就是不会调用getter方法。

那么为什么网上的payload可以攻击成功呢?
首先看下网上的payload
1 | String text1 = "{\"@type\":\"com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl\",\"_bytecodes\":[\"xxxxxxx\"],'_name':'a.b','_tfactory':{ },\"_outputProperties\":{ }," + |
在getOutputProperties处打个断点,发现确实可以执行到该方法,并且也没有调用toJSON。
1 | getOutputProperties:507, TemplatesImpl (com.sun.org.apache.xalan.internal.xsltc.trax) |
根据调用栈可以看到,还是通过调用setter方法调用的getOutputProperties,这是怎么做到的,查看setValue方法,发现在调用时,将 fieldInfo.method属性设置为getOutputProperties。通过前面对于反序列化流程的分析,这个值主要是在com.alibaba.fastjson.util.JavaBeanInfo#build中设置的。
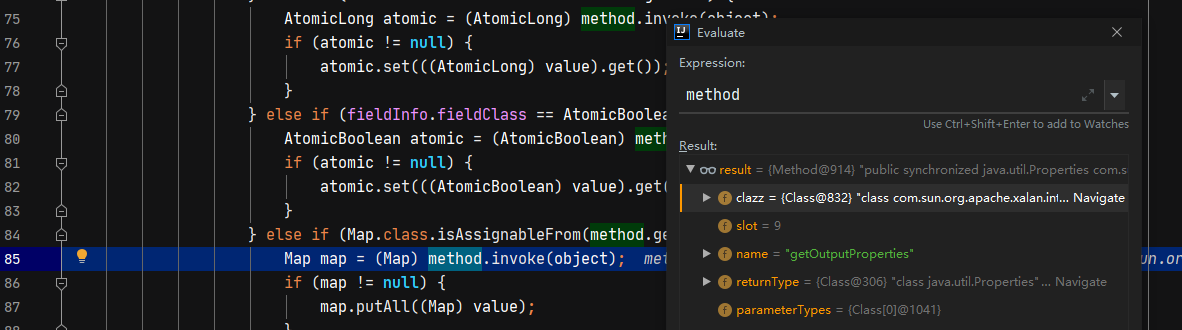

在构建JavaBeanInfo过程中,会获取构造方法,和属性的public的getter和setter方法,再根据beaninfo的信息通过asm动态生成javabean反序列化器,在反序列化器中只会调用setter方法,不会调用getter方法,那么为什么在这个栗子中getter方法会被调用呢?
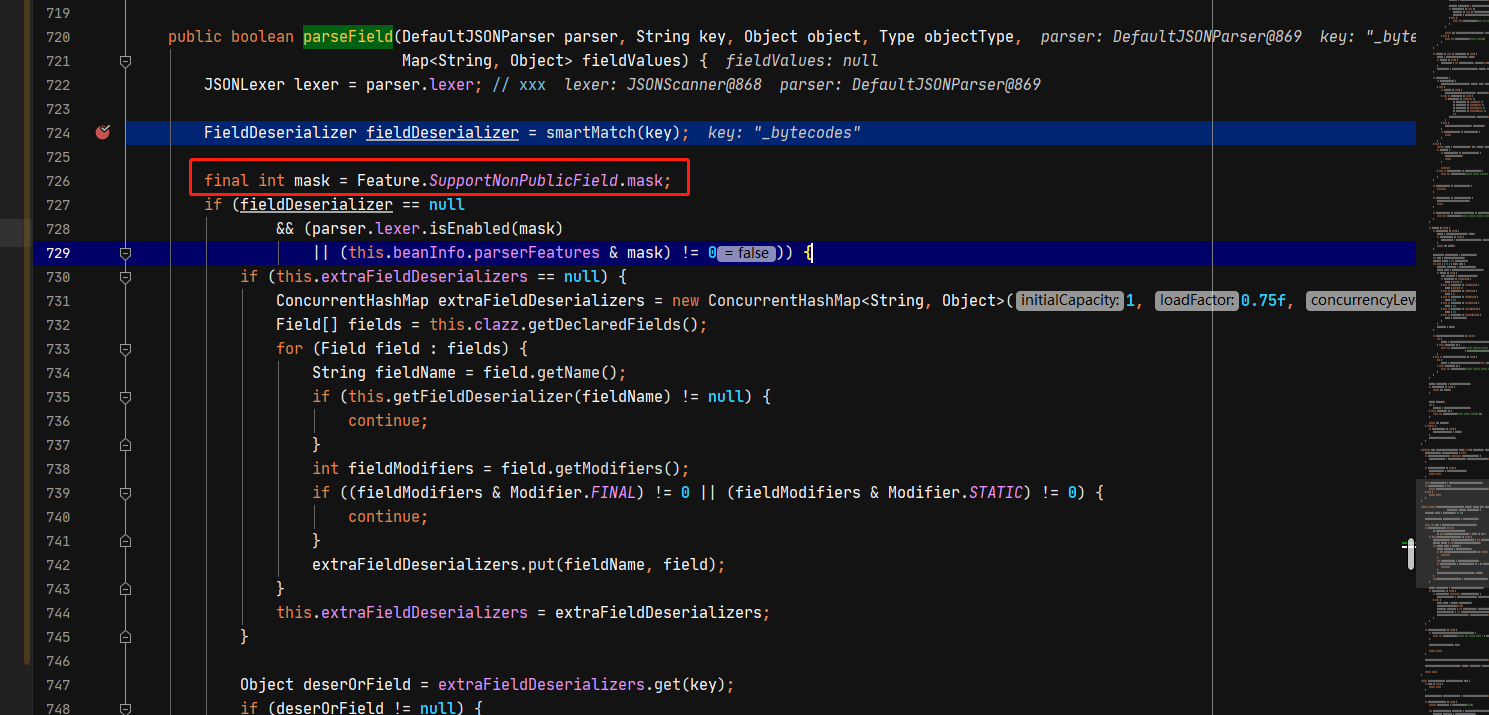
经过分析,asmEnable属性控制了是否通过asm创建反序列化器,当这个属性为false时,会直接创建JavaBeanDeserializer对象作为反序列化器,而不会通过asm动态生成。
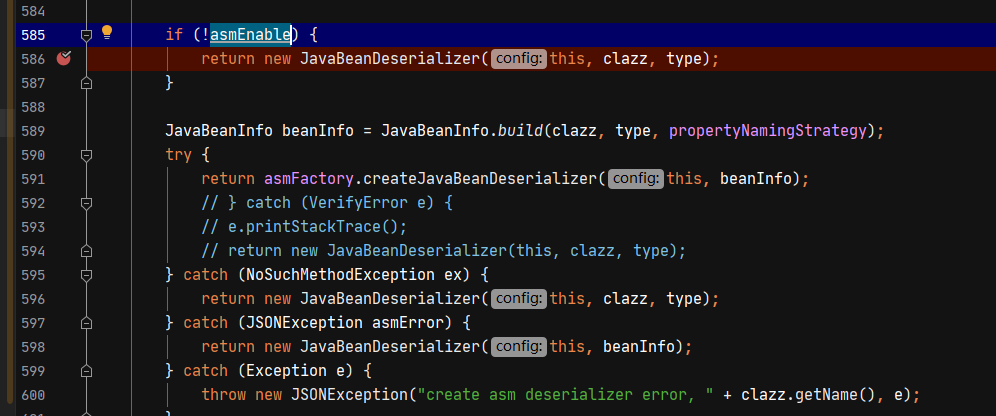
而在处理outputProperties属性时,由于getOnly属性为true,会将asmEnalbe的值设置为false,也就是不会通过asm动态创建反序列化器。

在FieldInfo的构造方法中,当方法的参数不为1个时,会给这个属性设置为true。
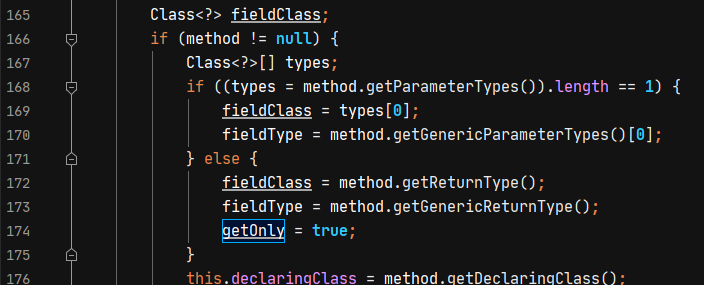
原本我猜想是因为getOutputProperties方法只有public的getter方法,没有setter方法所以getOutputProperties才会被设置到method属性中,但我用自己编写的demo测试并没有成功。所以还要分析在com.alibaba.fastjson.util.JavaBeanInfo#build中,满足什么条件的getter方法才会被设置。可以看到除了要满足以get开头的非静态方法,且参数为空之外,还要满足返回类型是为Map\Collection\AutomicBoolean等类型的子类或者实现类。
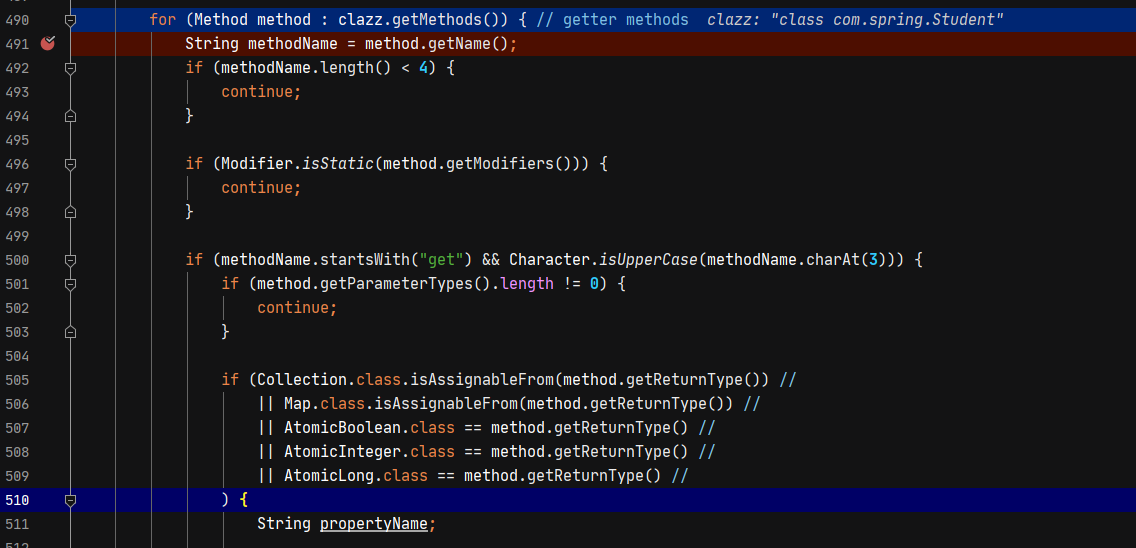
而getOutputProperties的返回类型Properties其父类正好是Map的实现类,因此满足条件。
上面我们已经分析了getOutputProperties对反序列化过程改变的原因,现在由于使用JavaBeanDeserializer构建反序列化器,之后的行为也会发生一些改变,在JavaBeanDeserializer中,首先会创建一个实例。
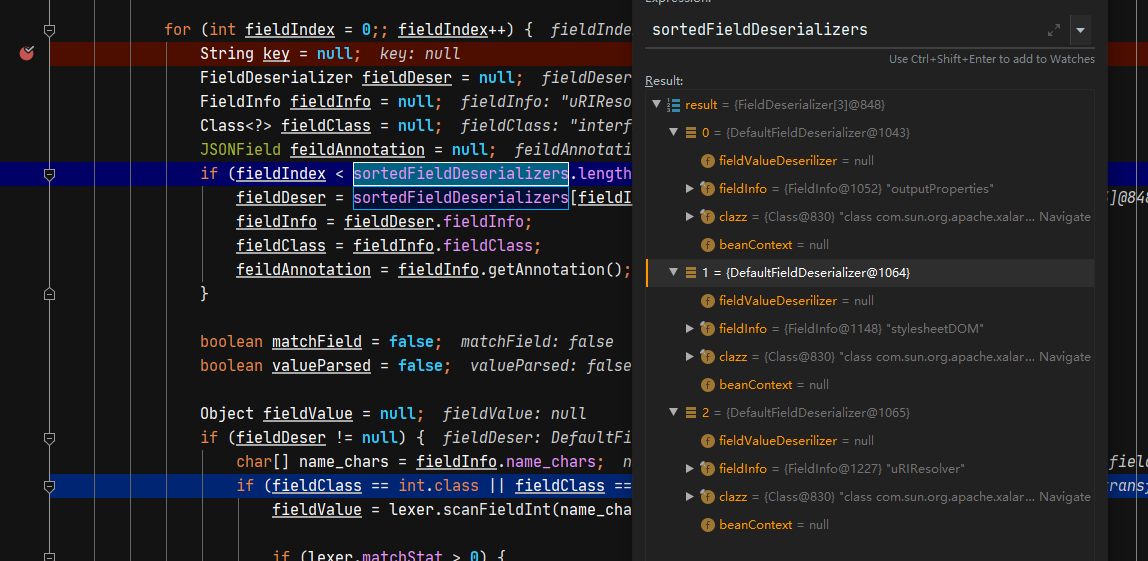
下面循环给实例的属性赋值,首先从sortedFieldDeserializers中解析反序列化器,并判断这些反序列化器的类型是否为基本类型,如果是基本类型则读取对应字段的内容进行处理,如果不是则跳过。
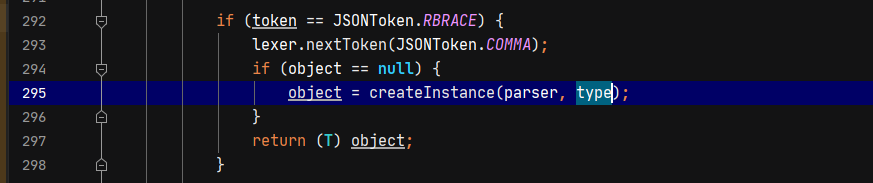
下面通过词法解析获取key的内容,判断key的内容是否为$ref或@type等引用类型,如果不是则通过parseFiled解析value的内容并赋值给object对象。

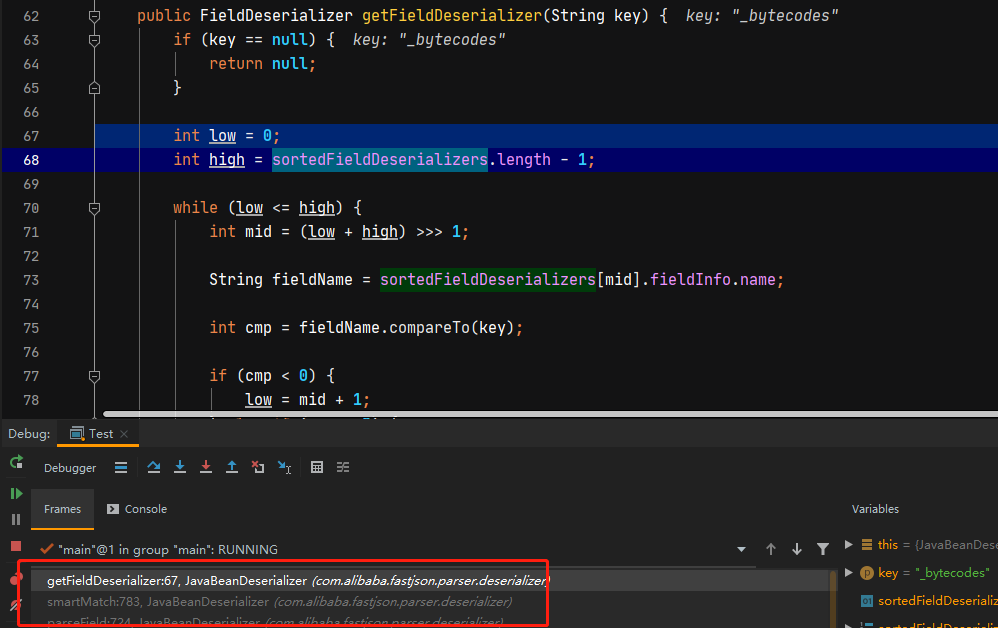
在com.alibaba.fastjson.parser.deserializer.JavaBeanDeserializer#parseField中获取字段的反序列化器并通过parseFiled进行解析。

在com.alibaba.fastjson.parser.deserializer.DefaultFieldDeserializer#parseField中,通过反序列化器对value的内容进行处理后,通过setValue将值赋值给对象。

当getOnly为true且method的返回值为Map的子类或者实现类时,会通过反射调用调用对应的方法。
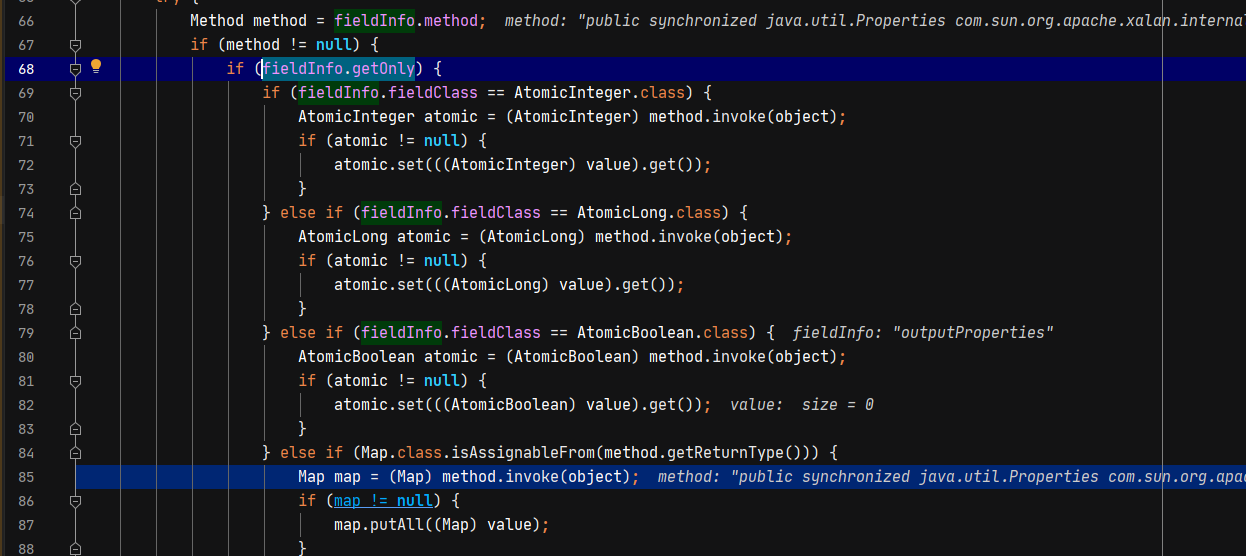
为什么设置了SupportNonPublicField后可以完成利用?
在com.alibaba.fastjson.parser.deserializer.JavaBeanDeserializer#parseField中会解析字段的值,如果没有设置Feature.SupportNonPublicField属性,则只会在smartMatch中通过之前解析到的sortedFieldDeserializers寻找反序列化器,不会通过其他方式获取Filed反序列化器。
最后我们对TemplateImpl这种利用方式做一个总结,首先由于 _bytecodes和 _name属性的setter方法不是public的,所以默认情况下无法调用,因此需要在parseObject加上SupportNonPublicField,但是加上这个设置后就无法通过toJSON调用getter方法,但是getOutputProperties返回类型是Map的子类,所以在javaBeanInfo.build的过程中,可以得到getOutputProperties方法并设置到filedInfo中,由于getOutputProperties没有一个参数的方法,所以不会通过asm动态构建反序列化器而是使用JavaBeanDeserializer构造,当解析到OutputProperties属性时,通过反射调用了getOutputProperties方法完成利用。据作者所说,这个利用链是参考jackson反序列化利用链找到的,我没了解过jackson是如何解析json数据的,可能他们的解析存在一种共性,所以导致利用链也可以迁移。